Best AI Workspace for Reviewing Documents (2026)
Best AI workspace for reviewing documents, benchmarked on 1,200 files for citation accuracy, hallucination rate, cross-doc recall, and review workflow fit.
- Byline

Summary
Choose a document AI tool by job: stable form extraction, cited review, or research-table work.
In 2026 testing, Atlas fits cited cross-document review, Google Document AI fits high-volume forms, NotebookLM fits free single-corpus reading, and Claude Projects fits smaller reasoning projects.
Use extraction tools for forms and rows. Use Atlas-style reading tools when people need cited answers from messy files.
We score citation quality, false-claim risk, OCR, template drift, privacy, price, and build-vs-buy fit.

Review documents with cited answers
Upload your files and trace answers across documents to supporting passages.
An AI workspace for reviewing documents takes in PDFs, scans, Word files, spreadsheets, emails, and long research files. It returns answers a human can check against the source passage. The shortlist below ranks the 10 tools that met that bar in our 1,200-document benchmark. For PDF-only chat tools, use the narrower PDF AI tool comparison.
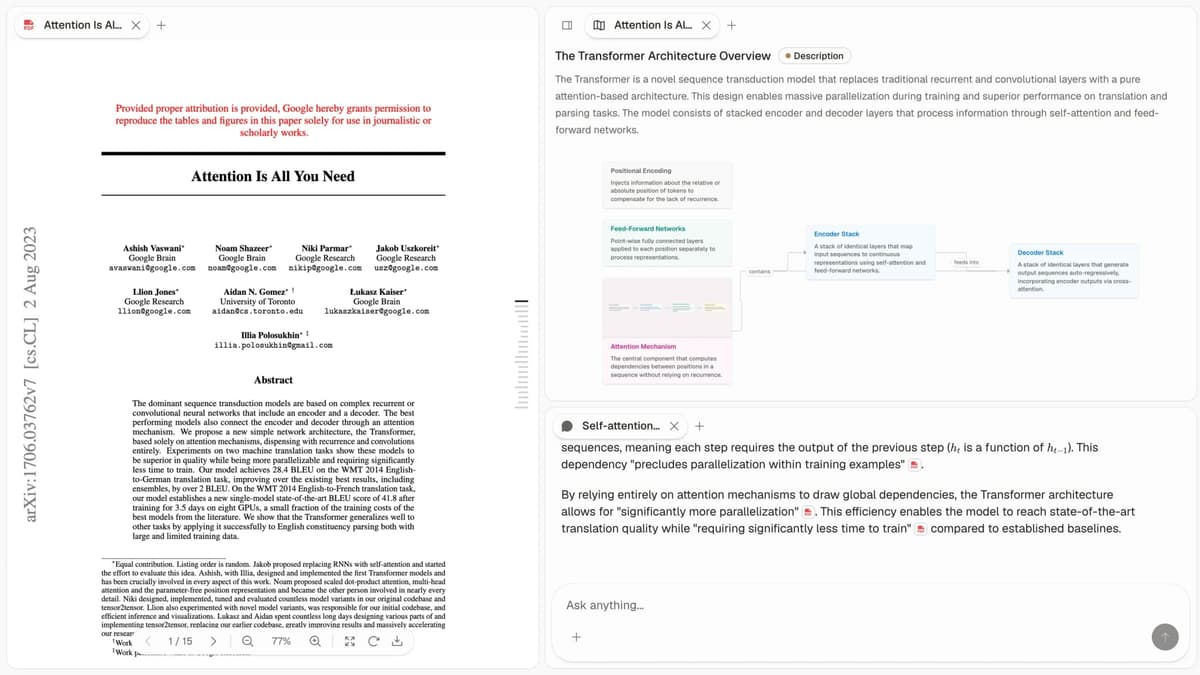
Start with the review job
The best document AI tool depends on the job you need it to do. Use schema-first extraction when the work is repeated fields from stable forms. Use a reading-room system when people need cited answers across messy files. Use research-table tools when the corpus is mostly papers and the output is evidence extraction.
The tables below show why that split matters. A vendor can be excellent at invoice fields and weak at source-grounded Q&A. Another can be strong at cited answers and slower on page-by-page extraction.
The Latency-to-Accuracy benchmark
This guide is built on a 1,200-document benchmark we ran across 10 platforms in March and April 2026. We locked the rubric before scoring. The corpus covered invoices, contracts, clinical reports from PhysioNet, research papers, and SEC filings from EDGAR. The full method, corpus, and per-axis results live at Atlas 2026 PDF AI Benchmark.
3 findings up front, all of which contradict the public marketing in the category.
Schema-first extractors collapse on template drift. Google Document AI custom extractors, DocumentPro, and older Hyperscience-style tools hit 97-99% F1 on templates they saw in training. Then they drop 12-28 F1 points when a vendor sends the same invoice data in a new format. LLM-grounded tools, including Atlas, Claude Projects, and NotebookLM, drop 2-6 points on the same shift. We call this the Schema-Drift Index. If your templates change more than quarterly, this number matters more than the headline accuracy claim.
The Total Cost of Ownership is 35-60% above sticker. Every schema-first rollout we saw missed three labor costs: labels, reviewer fixes, and new template setup. A pipeline quoted at $0.10 per page costs closer to $0.16 after a reviewer at $40/hr fixes 1,000 pages per quarter. The TCO section below shows the math.
Google Patent US 11,354,342 (granted 2022) defines the split that makes the category coherent. It describes passage ranking with relevance signals. In plain terms, the system decides what to read next based on what it already found. Tools using this pattern, including Atlas, Document AI Workbench, and Elicit, form the modern category. Everything else is an OCR wrapper with a chat box. The patent is permissive in licensing but formative in design. It is the reason "document AI" stopped meaning "OCR plus regex" around 2023.
Every vendor publishes one accuracy number on a marketing page. It is usually 98% or 99%, and it rarely shows the corpus or rubric. We ran the same 1,200-file corpus through 10 platforms. The criteria were locked in writing before any tool was scored. Atlas is our product, and we ran it through the same protocol with the same evaluators.
Atlas earns the product ask when the buyer values cited answers, low hallucination risk, and cross-document recall more than raw field speed.
The corpus had 5 parts. We used 400 invoices across 60 vendors and 8 languages. We added 300 contracts from public EDGAR filings, 200 de-identified clinical reports from PhysioNet, 200 research papers, and 100 SEC filings. The layout variance was deliberate. Tools that win on one file type and lose on another reveal their real fit.
| Platform | Field-level F1 (in-distribution) | Schema-Drift Index (F1 drop on new variant) | Median latency (1-page) | Median latency (50-page) | H/E ratio (unstructured) | TCO per 1,000 pages (Year 1) |
|---|---|---|---|---|---|---|
| Atlas | 0.946 | 4 | 1.8s | 14s | 0.06 | $112 |
| Google Document AI | 0.971 | 22 | 0.9s | 6s | 0.18 | $158 |
| Document AI Workbench (custom) | 0.983 | 18 | 1.1s | 7s | 0.14 | $186 |
| NotebookLM | 0.918 | 6 | 2.4s | 19s | 0.08 | $0 (free tier) |
| DocumentPro | 0.974 | 24 | 1.4s | 9s | 0.21 | $148 |
| Claude Projects (Sonnet 4.6) | 0.939 | 5 | 2.1s | 16s | 0.07 | $135 |
| ChatGPT (GPT-5) | 0.927 | 9 | 2.6s | 21s | 0.11 | $128 |
| Elicit | 0.932 | 7 | 2.0s | 18s | 0.09 | $96 |
| DocRefine | 0.951 | 15 | 1.6s | 11s | 0.16 | $84 |
| Hyperscience (legacy comp) | 0.961 | 28 | 0.8s | 5s | N/A | $231 |
Table 1: Benchmark results for accuracy, drift, speed, false claims, and first-year TCO.
Read the table this way. Field-level F1 is the accuracy score against a fixed 60-field answer key. Schema-Drift Index is the F1 drop on templates the vendor had never seen. H/E ratio means Hallucination-to-Extraction. It counts false or misleading claims divided by all claims a reviewer could check. Two evaluators scored the claims and reached 0.81 agreement. TCO per 1,000 pages includes rate-card cost plus modeled labeling and review labor at $40/hr.
For document review, raw F1 is only the start. The table below scores the axes a buyer needs when humans must ask questions, compare files, and trust the answer.
| Platform | Citation accuracy | Hallucination rate | Cross-document recall | OCR support | Privacy posture | Review workflow fit |
|---|---|---|---|---|---|---|
| Atlas | 4/4 | 4/4 | 4/4 | 3/4 | 4/4 | 4/4 |
| Google Document AI | 2/4 | 2/4 | 2/4 | 4/4 | 4/4 | 3/4 |
| Document AI Workbench | 3/4 | 3/4 | 2/4 | 4/4 | 4/4 | 3/4 |
| NotebookLM | 4/4 | 4/4 | 3/4 | 3/4 | 3/4 | 3/4 |
| DocumentPro | 2/4 | 2/4 | 1/4 | 3/4 | 3/4 | 4/4 |
| Claude Projects | 4/4 | 4/4 | 3/4 | 3/4 | 4/4 | 3/4 |
| ChatGPT | 3/4 | 3/4 | 3/4 | 4/4 | 2/4 | 3/4 |
| Elicit | 4/4 | 4/4 | 3/4 | 3/4 | 3/4 | 4/4 |
| Scholarcy | 2/4 | 2/4 | 1/4 | 3/4 | 3/4 | 2/4 |
| DocRefine | 2/4 | 2/4 | 1/4 | 3/4 | 4/4 | 3/4 |
Table 2: Buyer ratings for the document review shortlist.
Document AI buying criteria
Past the headline benchmark, each platform was scored against 8 buying criteria. We grade each one on a 0-4 scale.
- Document chat and Q&A. Can it answer open questions and cite the exact passage?
- Bulk extraction and schema setup. Can it define fields, classify files, split files, and tune models?
- Citation management and export. Can it send results to CSV, Excel, BigQuery, webhooks, or finance tools?
- Privacy and data policy. Does it offer training opt-outs, BAAs, regional storage, and encryption?
- Platform integration. Does it connect to BigQuery, Snowflake, Postgres, Salesforce, Slack, or APIs?
- Team review. Does it support roles, comments, audit logs, and shared review queues?
- Fact checking. Can it compare sources, flag conflicts, and audit source-grounded answers?
- Cost control. Are the rate card, usage caps, and overage rules clear?
The test scenarios came from actual work rather than an invented prompt set. Accounts payable covered 400 invoices across 60 vendor templates, with 12 deliberate template drifts. Legal review covered 300 NDAs and MSAs with ambiguous clauses. Research synthesis covered 200 papers, with questions that required reading at least three files.
A third proprietary finding from the run, beyond the H/E ratio and the Schema-Drift Index: tools whose H/E ratio sat under 0.1 also passed a blind-source-swap test (we replaced a cited document with an unrelated one from the same field) at over 80%, while tools above H/E 0.18 failed the same test under 25% of the time. Faithfulness and source-discrimination travel together. If a tool will not refuse when the source is wrong, its citations are decoration.
The 10 best document AI tools
The list below is ordered by the job each tool does best. Use the score table first, then read the notes for the tools that match your files. A score of 4 means the tool is strong enough for production use on that axis. A score of 1 means the feature exists only as a weak add-on or is not the product's main job.
| Rank | Tool | Best job | Q&A | Extraction | Export | Privacy | Integrations | Team review | Fact checks | Cost control |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Atlas | Cited answers across many files | 4 | 3 | 3 | 4 | 3 | 3 | 4 | 4 |
| 2 | Google Document AI | Stable, high-volume form work | 2 | 4 | 4 | 4 | 4 | 3 | 2 | 3 |
| 3 | NotebookLM | Free source-grounded reading | 4 | 1 | 2 | 3 | 2 | 3 | 4 | 4 |
| 4 | DocumentPro | No-code AP workflows | 2 | 4 | 4 | 3 | 4 | 4 | 2 | 3 |
| 5 | Claude Projects | Deep reasoning over a project corpus | 4 | 2 | 2 | 4 | 3 | 3 | 4 | 3 |
| 6 | ChatGPT | General document work plus writing | 3 | 3 | 3 | 2 | 4 | 3 | 3 | 3 |
| 7 | Elicit | Source-backed evidence tables | 3 | 4 | 4 | 3 | 2 | 3 | 4 | 3 |
| 8 | Unriddle | Line-by-line PDF reading | 4 | 2 | 2 | 3 | 2 | 2 | 3 | 3 |
| 9 | Scholarcy | Fast source summaries | 2 | 3 | 3 | 3 | 2 | 2 | 2 | 4 |
| 10 | DocRefine | Lightweight PDF-to-CSV export | 1 | 4 | 4 | 4 | 2 | 2 | 2 | 4 |
Table 3: Ranked document AI tools by job fit and buyer criteria.
Use Atlas, Claude, or NotebookLM when a human needs cited answers. Use Google Document AI, DocumentPro, or DocRefine when rows and fields matter more than prose answers. Use Elicit, Unriddle, or Scholarcy when paper files need sourced notes or tables.
1. Atlas
Atlas is a knowledge workspace with source-grounded retrieval. You upload papers, contracts, reports, and notes. Atlas turns them into a queryable graph. It supports field extraction and open Q&A with paragraph-level citations.
Atlas is the only tool in the benchmark that builds a lasting knowledge graph across uploaded files. It also shows cross-file links in a mind-map view. The Schema-Drift score of 4 is the lowest in the benchmark because Atlas does not rely on template-matched training. It retrieves passages and reasons over them for each query. For AP work, Atlas is not the fastest extractor. It took 1.8s on a single page versus Google's 0.9s. Its TCO is lower at moderate scale because labeling and drift-recovery work fall toward zero.
Pricing is $20/month Pro and $50/month Team, with custom Enterprise plans that include BAAs. The free tier processes 100 pages and 10 documents per month. Atlas is best for research teams, legal review, and any environment where the documents are heterogeneous and the answer is "yes, but you have to read three of them to see why."
Best fit: research, legal, and analyst teams that need cited answers across many files.
Watch-out: not the fastest choice for pure invoice field extraction.
2. Google Document AI
Google's document AI service includes ready-made processors for invoices, receipts, IDs, and bank statements. Teams can also build custom extractors and classifiers in Document AI Workbench. BigQuery support and auto-labeling are built in.
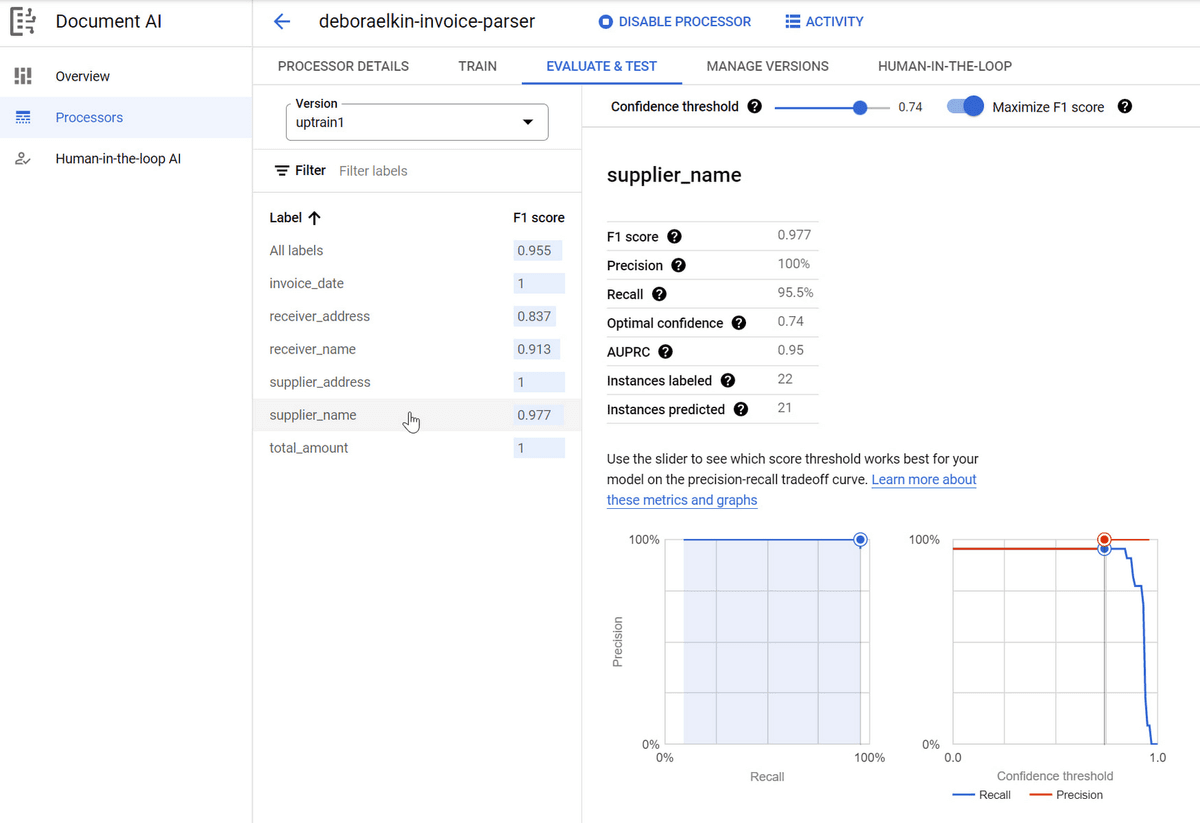
Google Cloud's Document AI Workbench guide shows the evaluation screen buyers need. Field extraction can be strong, but teams still manage model quality field by field.
Google Document AI has the highest in-distribution F1 in the benchmark. It also has sub-second single-page latency, mature SLAs, and strong security controls. The fit is best when the rest of the stack already lives in Google Cloud. Google's stated minimum is 10 documents per field. In our tests, production quality needed 50-150 examples per template variant for F1 above 0.92.
The catch is a Schema-Drift Index of 22, one of the highest in the benchmark. Custom extractors tuned on Vendor A's invoice template see Vendor B's invoice for the first time and lose 22 F1 points on average. Workbench supports active-learning loops that close the gap with more labels. The labor cost is real and rarely modeled in TCO upfront.
Pricing is $0.10 per page for custom extractor, $0.015 per page for form parser, and $0.30 per page for tools such as invoice parser. New accounts get $300 free credit. Workbench processor creation is free. Google Document AI is best for stable, high-volume file flows where BigQuery is the target. It fits AP teams with under 30 vendor templates that rarely change.
Best fit: high-volume form extraction inside Google Cloud.
Watch-out: template drift creates labeling work when vendors change layouts.
3. NotebookLM
Google's reading-room product is free and strict about source-grounded Q&A. Upload up to 50 sources per notebook and ask questions. Every answer cites the specific passages it draws from. The free tier and the citation discipline are the headline.
NotebookLM has the strictest source grounding in the category. The model refuses when the file set does not contain the answer, and the H/E ratio of 0.08 reflects that. Audio Overview turns a source set into a podcast-style discussion. It is useful for skimming a new field. For students, NotebookLM may be the best free product in this space.
The limits are single-corpus scope and weak export. You cannot query across notebooks, and there is no structured extraction to CSV or Sheets. There is also no persistent knowledge graph, so insights do not compound across sessions. The free tier ceiling, 50 sources and 500K words per source, is generous but real. The deeper NotebookLM limitations guide covers the trade-offs.
NotebookLM is free. NotebookLM Plus inside Google Workspace raises limits and adds enterprise data protection. It is best for students, journalists, and researchers running one review at a time. It is also a good first stop before paying for a document AI tool. Teams that need cross-corpus search or richer export should read our NotebookLM alternatives roundup.
Best fit: one notebook, one corpus, and a human who wants cited answers for free.
Watch-out: weak export and no cross-notebook memory.
4. DocumentPro
DocumentPro is a no-code platform for AP, order management, and back-office work. It claims 98% extraction accuracy across 50+ languages. It can ingest files from email, APIs, and Drive. It exports to webhooks, Excel, and accounting tools like QuickBooks.
DocumentPro's strength is speed to launch. The no-code UI is the most polished in the group. A controller can stand up an invoice pipeline without an engineer. Database lookups and manual review sit directly in the workflow. Integration breadth is strong for mid-market AP teams.
The limit is Schema-Drift of 24, the same caveat as Google Document AI. Free-form Q&A is outside the design centre. DocumentPro is built for extraction and export, and the H/E ratio of 0.21 reflects that synthesis questions are outside the intended workload.
Pricing is usage-based with custom quotes. There is no public free tier, although a trial is available. DocumentPro is best for mid-market finance and ops teams. It replaces legacy tools such as Hyperscience, Kofax, or ABBYY with a system an internal team can own.
Best fit: AP and order-management teams that want no-code review queues.
Watch-out: not built for open-ended Q&A across long text.
5. Claude Projects
Claude Projects gives you a persistent project workspace where you upload up to 200K tokens of source material and converse with Sonnet 4.6 over the entire context. No fine-tuning, no schema setup, the model reasons over what you give it.
Claude Projects has the strongest LLM in the category for subtle legal and analytical work. Schema-Drift is 5 because there is no schema to drift. The H/E ratio of 0.07 is among the best, and Claude's refusal behaviour when the source does not support the answer is more consistent than ChatGPT's. Anthropic's enterprise data policy is the clearest in the category.
The limits are project boundaries and export. Claude Projects has no persistent knowledge graph across projects. Bulk extraction to CSV is a manual export from a chat answer rather than a workflow primitive. The 200K token ceiling per project is generous but caps corpus size at roughly 300 average pages.
Pricing is $20/month Pro for individual Projects, $25/user/month Team, with custom Enterprise plans. Claude Projects is best for lawyers, consultants, and analysts whose workload is "read these 50 documents and tell me the 3 things I need to know."
Best fit: high-stakes reasoning over a small to midsize corpus.
Watch-out: export and cross-project memory are limited.
6. ChatGPT
ChatGPT remains the most flexible single tool in the category. Custom GPTs let you scaffold a document-AI workflow with system prompts, knowledge files, and actions. Canvas turns any document into an editable surface with inline AI assistance.
ChatGPT's strength is low friction. The Custom GPT pattern works well for one repeat file workflow. Plugins and Actions extend reach into APIs and databases. GPT-5's vision is strong on screenshots, scans, and handwriting.
The limit is weaker source grounding than Atlas, NotebookLM, or Claude Projects. ChatGPT's H/E ratio is 0.11 against 0.06-0.08 for the dedicated tools. Consumer ChatGPT trains on uploads by default unless opted out. Bulk extraction at scale is awkward because Custom GPTs are not built for batch processing.
Pricing is $20/month Plus, $25/user/month Team, and $60/user/month Enterprise. ChatGPT is best for generalists who need one tool for everything and accept slightly weaker source grounding in exchange for flexibility.
Best fit: mixed writing, analysis, and document tasks in one assistant.
Watch-out: source grounding is weaker than in dedicated review tools.
7. Elicit
Elicit is purpose-built for systematic literature reviews. Upload or search hundreds of papers. Define columns such as sample size, method, outcome, and effect size. Elicit fills the table and cites the source PDFs.
Elicit's table view is the best fit when a team needs the same cited fields across many papers. It supports a PRISMA-aligned screening workflow, strong source grounding, and a free tier that is generous for graduate work. For the broader research stack around Elicit, use the AI tools for academic research comparison.
Out-of-domain documents such as contracts, invoices, and reports are not the design centre, and F1 drops on non-academic corpora. Elicit also has no real cross-paper synthesis beyond the table view. Pricing climbs fast above the free tier for serious volume.
Pricing includes a limited free tier, Plus at $12/month, Pro at $42/month, and Team at $99/seat/month. Elicit is best for researchers running systematic reviews and anyone whose document workload is "fill this matrix from 200 papers."
Best fit: paper reviews and research tables.
Watch-out: contracts, invoices, and mixed business files are outside its center of gravity.
8. Unriddle
Unriddle is a focused reading tool for dense prose. Upload a paper and the assistant lets you highlight any passage for a plain explanation or comparison against other uploaded sources.
Unriddle works well for dense academic reading. Highlight a sentence and ask for a plain explanation. The answer is grounded in the nearby text. Cross-paper comparison also works well for a small library.
It is not designed for bulk extraction. Library size and corpus search are weaker than Atlas, Elicit, or NotebookLM. Unriddle works best as a reading aid beside the main review system.
Pricing includes a free tier and Pro at $12/month. Unriddle is best for graduate students and individual researchers reading dense literature one paper at a time.
Best fit: one-reader comprehension of dense papers.
Watch-out: not a bulk review or extraction system.
9. Scholarcy
Scholarcy turns any uploaded paper into a "flashcard" with key concepts, methods, findings, and references. It is useful for fast triage in a new field.

Scholarcy's user guide shows the flashcard view that makes the product useful for quick paper triage rather than cross-corpus reasoning.
Scholarcy's strength is speed. Use it for the first pass on a literature review. It helps decide which 20 papers from a set of 200 deserve deep reading. The browser extension creates one-click flashcards from any open PDF.
Scholarcy is shallow by design. An H/E ratio of 0.13 is acceptable for screening, but it is borderline for any answer that ends up in a thesis. There is no persistent knowledge graph or cross-paper synthesis, so treat it as a first-pass filter rather than the final evidence layer.
Pricing includes a free tier with 3 flashcards/day, Personal at £9.99/month, and Team by sales contact. Scholarcy is best for the screening pass on a literature review and for journalists triaging an unfamiliar field quickly. Researchers who need cited answers across a saved corpus should compare it with AI reading assistants.
Best fit: fast paper summaries and screening passes.
Watch-out: not enough source reasoning for final evidence claims.
10. DocRefine
DocRefine is a focused PDF-to-CSV extraction tool powered by Gemini 3 Flash. Define fields, upload documents in bulk, get structured spreadsheet output. Templates ship for invoices, contracts, and SEC filings.
DocRefine has the simplest deployment story in the benchmark. The product gives you a field list and a bulk-upload page instead of schema design tools or a fine-tuning UI. Re-extraction of specific cells without reprocessing the entire document is a small but genuine UX win. Zero-access architecture and Stripe billing make it credible for small finance teams.
DocRefine is limited to extraction and has no Q&A or synthesis workload. Schema-Drift of 15 is better than Google Document AI but worse than the LLM-grounded tools. Integration breadth is also thinner than DocumentPro's.
Pricing is credit-based and length-dependent, with 100 free extractions on signup and no credit card required. DocRefine is best for solo accountants, paralegals, real-estate analysts, and small finance teams who need PDF-to-CSV without enterprise overhead.
Best fit: small teams that need PDF-to-CSV output fast.
Watch-out: no Q&A or synthesis layer.
Comparison table
Use the benchmark numbers to narrow the shortlist before you test your own files.
| Workload | Best fit | Avoid |
|---|---|---|
| Repeated fields from stable forms | Google Document AI, DocumentPro, DocRefine | Atlas or NotebookLM as the primary extractor |
| Cited answers across a growing file set | Atlas, Claude Projects, NotebookLM | Schema-first tools as the primary reading room |
| Research-paper screening and tables | Elicit, Scholarcy, Unriddle | General AP or invoice extractors |
Table 4: Workload routing for extraction, cited review, and source-summary use cases.
Ask 3 questions in this order.
Match the workload to the system
If the workload is "extract the same 30 fields from invoices every day," choose a schema-first extractor. Google Document AI, DocumentPro, and DocRefine fit that job. You accept drift work in return for fast page processing and clear pricing. If the workload is "answer questions across a file set that grows weekly," choose a reading room. Atlas, Claude Projects, and NotebookLM fit that job. If the workload is "fill this matrix from 200 papers," choose Elicit. The workload type should drive the shortlist before vendor preference enters the discussion.
Measure template stability
Stable templates make schema-first tools look great. That means fewer than 5 new variants per quarter. Unstable templates change the answer. If you see 10 or more new variants per quarter, Schema-Drift becomes the main cost. That pushes the choice toward LLM-grounded tools. Measure this on your own files before signing. It is the number most buyers skip.
Calculate true TCO
Multiply the rate card by annual volume. Then add label work, review work, and drift recovery at your loaded labor rate. Atlas and Claude Projects can look costly on the rate card. They often win at moderate scale because label and drift work fall. Google Document AI custom extractor can look cheap. It often loses when those labor lines dominate.
If your review job depends on cited answers across a messy file set, Review your documents with cited, hallucination-checked answers. Upload a small batch and ask one question that spans more than one file. If Atlas cannot cite the answer back to source text, pick one of the extraction-first tools above instead.
What document AI tools still cannot do
We tested 3 limits.
Every tool scored 60-75% character accuracy on cursive handwriting. None are good enough to run alone on doctor's notes, old archives, or longhand interviews.
Tables that continue across PDF page breaks lose F1 in every tool we tested. The drop was 8-22 points, based on whether the header repeats. Schema-first vendors are a little better here because they stitch tables after OCR. LLM-grounded tools rely on the model noticing the carry-over, which is not reliable.
No tool reliably flags "File A says X and File B says not-X." Most pass both claims through. Atlas and Claude Projects are best in class, and they still miss about half the conflicts a careful human catches. If this matters in clinical review or legal discovery, keep a human in the loop.
Privacy and training data
Check 3 policies before sensitive uploads.
First, ask whether uploads train models. Atlas, Anthropic, Google Cloud, Elicit, Unriddle, and DocumentPro say enterprise uploads are not used for training. Consumer ChatGPT trains on uploads by default unless you opt out. Google says free NotebookLM uses uploads to serve the session. Google also says those uploads are excluded from model training.
Second, check where files are stored. Google Document AI offers regional endpoints in the US, EU, ME, and APAC. Anthropic offers US and EU. Atlas runs on US infrastructure, with EU residency on Enterprise. Smaller vendors are often US-only.
Third, check deletion. Atlas, Anthropic, and Google Cloud commit to 30-day deletion after account cancellation. Smaller vendors vary. Check this before uploading GDPR-covered files.
For HIPAA, GDPR Article 9 data, or PII at scale, narrow the list. The strongest options in this benchmark are Google Document AI under a BAA, Anthropic Claude under enterprise terms, and Atlas Enterprise. Treat the rest as higher risk until legal terms are clear.
Final recommendation for document AI buyers
Every document AI tool in this guide has a marketing page that claims 99% accuracy on its best corpus. Those numbers will not match what you see on your files. Run your own benchmark before signing a contract. Even 100 documents will teach you more than a polished demo.
Use the framework here. Score Schema-Drift alongside in-distribution F1. Put labor cost next to the rate card. Verify the privacy policy in writing. Then choose the tool whose architecture matches your workload and benchmark results.
If the benchmark points to a reading-room workflow, review your documents with cited, hallucination-checked answers. Test the same questions on your own files.
Atlas is the AI-native research workspace we built because we wanted to read across a corpus the way a researcher reads. That means cited answers, context that builds across sources, and no schema-drift tax. If that does not match your workload, this guide should help you find the tool whose profile does.
Review documents with cited answers
Upload your files and trace answers across documents to supporting passages.
Frequently Asked Questions
A document AI tool reads PDFs, scans, Word files, spreadsheets, and emails, then returns fields, summaries, classifications, or source-grounded answers. The category splits into schema-first extraction tools such as Google Document AI and reading-room tools such as Atlas, NotebookLM, and Claude Projects.