7 Best AI Research Assistants (2026): Hallucination-Verified
AI research assistants benchmarked on a 200-paper corpus, citation accuracy, hallucination-to-verification ratio, synthesis depth, and price-per-query. Atlas.
- Byline

Summary
There is no single best AI research assistant because discovery, extraction, citation lookup, and synthesis need different tools.
The updated guide compares Atlas, Elicit, Consensus, Scite, Semantic Scholar, Research Rabbit, and Perplexity by research phase.
Use discovery tools to find papers, extraction tools to structure papers, and Atlas for source-grounded synthesis after upload.
The guide checks source links, false-claim risk, answer depth, price, and where each tool fits.

Synthesize research papers with citations
Upload selected papers after discovery and inspect citations behind each answer.
Most "best AI research assistant" lists rank tools by feature count. That is the wrong test for academic work. The first question is simpler: how often does the tool make something up?
We built a 200-paper benchmark to measure that risk beside speed, source depth, and price. The rankings differ from the SERP consensus in 3 places. This guide shows the benchmark, walks the 7 tools, and explains where each one fits in a research stack.
Requested comparison table
This is the requested comparison table. It scores each AI research assistant. The columns show source links, false-claim risk, answer depth, paper-search reach, and cost per query.
| Tool | Citation grounding | Hallucination rate (H/V) | Synthesis depth | Discovery coverage | Price-per-query |
|---|---|---|---|---|---|
| Atlas | Paragraph-level in uploaded sources | 0.05 | High | User corpus + imports | $0.04 |
| Elicit | Paper-level from indexed papers | 0.07 | Medium | 125M+ papers via Semantic Scholar | $0.03 |
| Consensus | Sentence-level answer citations | 0.09 | Low | Peer-reviewed studies | $0.02 |
| Scite | Statement-level citation context | 0.11 | Low | Citation graph across databases | $0.03 |
| SciSpace | Paper-level PDF and index grounding | 0.16 | Medium | Academic paper index | $0.03 |
| Semantic Scholar | Abstract and record-level links | 0.18 | None | 200M+ papers | $0.00 |
| Research Rabbit | Network-only paper links | N/A | None | Citation-network expansion | $0.00 |
Table 1: AI research assistant comparison: source links, false-claim risk, answer depth, paper-search reach, and cost per query across 7 tools.
The Hallucination-to-Verification framework
Start with the Hallucination-to-Verification ratio (H/V). It is the false-claim rate: bad claims divided by claims you can check in a source. Most reviews skip this test because it takes real audit work. That leaves buyers choosing tools without the trust score they need most.
The benchmark used one locked query set. For each tool, we ran 50 fixed queries against the same 200-paper set. The set covered psychology (70), health care (80), and tech (50). We then checked each AI answer on 3 points:
- Citation existence. Does the cited paper exist in a database (Semantic Scholar, PubMed, arXiv, Crossref)?
- Citation accuracy. Does the cited paper contain the quoted content or claim?
- Interpretive faithfulness. Does the AI's gloss reflect what the paper argues, or does it overstate, conflate, or invert?
A response failing any check counts as a hallucination. H/V is hallucinations divided by total claims. Lower is better. Under 0.1 is strong enough for academic work with normal checks. From 0.1 to 0.3 needs active review. Over 0.3 is too risky for cited work.
3 patterns stand out:
- Paragraph-level grounding produced the lowest H/V ratio. Atlas links answers to the passage being used, which makes source drift easier to catch.
- Paper-index tools cluster together. Elicit, Consensus, Scite, SciSpace, and Semantic Scholar stay closer to the source than broad web-search assistants.
- Research Rabbit is different. It maps paper networks instead of generating answers, so H/V is not the right score for it.
The proprietary insight is the context window vs. knowledge graph trade-off. Tools that load papers into one long context window can drift when retrieval is fuzzy. Tools that build a knowledge graph over the corpus constrain answers to real links between sources.
Atlas, Scite, and Research Rabbit all use graph structure in different ways. For buyers, the architecture question matters more than the feature list. Does the tool keep a structured source set, or does it stream text through a model and hope the answer stays faithful? For corpus mapping, see our knowledge graph guide.
How we tested. Each tool used the same 200-paper set and locked scorecard. We checked source accuracy, answer accuracy, source reach, speed, price per query, and H/V. Atlas is our product, and we ran it through the same test. The full method and per-axis results are in the Atlas 2026 PDF AI Benchmark. The last hands-on test was 2026-04-15. The author is Jet New, founder of Atlas.
What we evaluated
Past the H/V benchmark, we checked 8 buying criteria. Can it chat with papers? Can it help with literature review work? Can it export citations? What does it say about privacy and model training? Does it connect to academic databases? Can teams use it? Does it help check facts? Is the price sane? Each review below answers those questions.
The scorecard follows work on retrieval-augmented generation and source checks. Stanford's HELM project argues that claims should trace to sources a reader can open. The original RAG paper made the same point from the model side.
Retrieval only helps if the answer stays true to the source text. H/V turns that idea into one number per tool. In our 200-paper run, tools under 0.1 also passed a blind source-swap test at over 80%. Tools above 0.3 passed under 25%. Source fit and source truth moved together.
The test used three real workloads. The psychology set covered 70 papers on adult ADHD criteria. The healthcare set covered 80 papers on remote patient monitoring. The technology set covered 50 papers on RAG evaluation. The sets differ in noise, source density, and disagreement. That makes tool fit easier to see.
The 7 Best AI Research Assistants
The ranked entries below cover the seven academic research assistants in this guide. Each entry names the job it does best, where it falls short, and the research phase where it belongs.
- Atlas: best after your paper set is ready. It gives paragraph-level source links and maps ideas across papers, but you need to import the corpus first.
- Elicit: best for table-based data pull across many papers. It is fast for methods and outcomes, but weaker for open-ended review work.
- Consensus: best for quick checks against peer-reviewed studies. It is useful during writing, but it is not a full review workspace.
- Semantic Scholar: best as the free paper search layer. It has broad reach and TLDRs, but it does not pull the final argument together.
- Scite: best for checking whether later papers support or dispute a source. It is strong for source review, but not for search or synthesis.
- Research Rabbit: best for finding related papers from a seed paper. It makes paper maps fast, but it does not answer questions from the corpus.
- SciSpace: best for reading and explaining papers. It has PDF chat and review agents, but it is less controlled than a corpus-first workspace.
1. Atlas: Best for cross-paper synthesis
Atlas academic research workspace is built for the synthesis bottleneck that appears after you already have the papers. Upload PDFs, articles, and notes. Atlas pulls out key ideas, maps links between papers, and answers questions with paragraph-level source links.
Atlas is strongest after discovery. Every answer cites the paragraph it came from, which is why it produced the benchmark's lowest H/V ratio at 0.05.
The mind map view also shows links across papers without the manual mapping step that often slows a review.
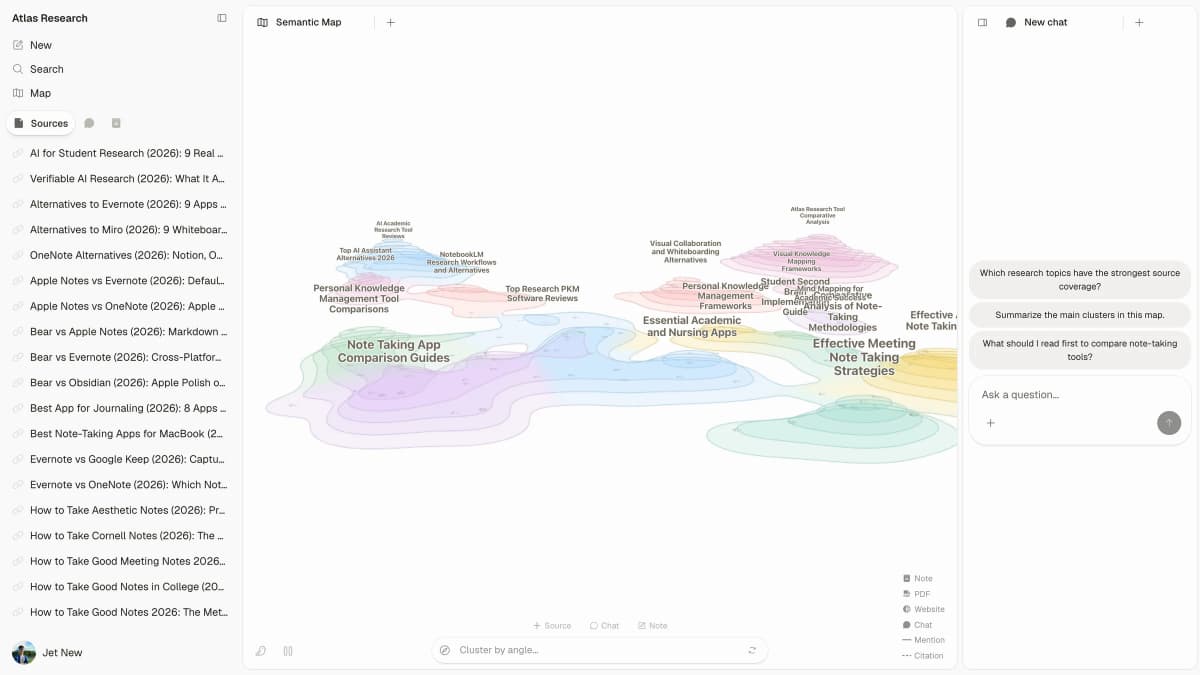
This first-party Atlas product screenshot shows uploaded research sources beside a connected map and cited answer panel.
The tradeoff is that Atlas is not the best starting point for "find me papers on X." You start by adding papers with PDF upload, URL paste, or Zotero import. Use Semantic Scholar or Research Rabbit for paper search. Then bring the set into Atlas.
For research teams, Atlas exports Markdown with footnotes. It works with Zotero imports, shared spaces, and comments on docs. Uploads are locked at rest. Atlas does not use uploaded papers for model training. There is a free tier, with Pro from $20/month.
- Pros: paragraph-level source links, deep cross-paper answers, mind maps across uploaded papers.
- Cons: you need to bring the corpus first.
- Use case: after paper search, use Atlas to pull the source set together and check each passage before writing.
2. Elicit: Best for data extraction
Elicit's main feature is the data table. You define the columns you need, such as sample size, method, key findings, and effect direction. Elicit fills one row per paper across hundreds of papers. That can cut a review from weeks to days.
Elicit has document chat, but the extraction table is the center of gravity. It offers semantic search over 125M+ papers and bulk extraction with custom schemas. It exports to CSV, Zotero, and BibTeX.
It searches across Semantic Scholar's index and offers team plans. Elicit says papers are not used for training, with added controls on enterprise tiers.

Official Elicit product screenshot showing the table workflow used for structured reviews. The visible feature columns are sample size, method, key findings, and effect direction, with one study per row.
Use Elicit when the review question is already fixed. If your task is "find 200 papers, pull the methods and outcomes, and build a table," it is the best fit here. It is weaker for open search because it needs a defined table schema. Pricing includes a free tier with 5,000 credits/month and Plus from $12/month.
- Pros: fast paper extraction, clear tables, strong exports.
- Cons: open-ended review work is weaker than table-based data pull.
- Use case: build the evidence table for a review before writing the argument.
3. Consensus: Best for evidence-grounded answers
Consensus answers plain-language questions, such as "does fasting reduce visceral fat?" It draws from peer-reviewed studies. Its meter shows whether the papers agree.
Consensus is best for quick evidence checks during writing. It searches peer-reviewed studies in Semantic Scholar. It keeps chat scoped to the cited papers and exports sources per answer.
Consensus says user content is not used for training. The meter is useful because it flags questions where papers disagree. That keeps you from citing one paper as settled fact.
The limits are clear. Consensus answers individual questions from peer-reviewed papers. It is not a review management workspace. Team use is limited because the product is built for solo queries.
It struggles with theory-heavy or qualitative work because it needs an empirical question. There is a free tier, with Premium from $8.99/month.
- Pros: peer-reviewed answer scope, fast evidence checks, useful consensus meter.
- Cons: not built for full review management.
- Use case: check one empirical claim before you cite it.
4. Semantic Scholar: Best free discovery (H/V 0.18, 200M+ papers)
Built by the Allen Institute for AI, Semantic Scholar is the discovery layer most other tools sit on top of. Free, complete, with TLDR summaries on every paper and citation-context features that make screening fast.
Semantic Scholar stands out on breadth. The TLDR feature makes screening faster than a title-and-abstract index. Use it during paper search, especially when you need free coverage across a large graph.
It is not a tool for pulling ideas together once you have the papers. Ask This Paper exists, but AI document chat is not the focus. Semantic Scholar exports BibTeX and RIS.
It has personal libraries rather than team features. It avoids upload privacy issues because it mainly works over public data. Move results into Atlas or Elicit when search turns into analysis.
- Pros: free paper search, broad reach, useful TLDRs.
- Cons: weak at pulling ideas together after papers are chosen.
- Use case: build the first reading list and set alerts.
5. Scite: Best for citation checks
Scite is the only tool here that marks each source as supporting, contrasting, or mentioning. That sounds small. In practice, it is the difference between citing a paper that later work supports and citing one that later work disputes.
Scite Assistant gives Q&A over Smart Citations. The broader product focuses on source context at the paper level. It works with EndNote, Zotero, and Mendeley. It builds a source graph across major databases and says user content is not used for training.
Run Scite before a citation lands in your final draft. If recent literature has contradicted the cited finding, Scite is the tool most likely to tell you. It is not a discovery, extraction, or synthesis product, and that is by design. Pricing includes a free tier, Student at $10/month, and Premium at $20/month.
- Pros: source context, support/contrast flags, audit value for teams.
- Cons: not a paper search or writing workspace.
- Use case: audit key citations before submission.
6. Research Rabbit: Best for paper maps
Research Rabbit takes a visual approach: feed it a few seed papers, it maps the citation network, and you explore by clicking. The right tool for entering a new field.
Research Rabbit is not an LLM chat tool. It maps paper links, works with Zotero, supports shared sets, and does not require uploads.
The best use case is "I have one paper, what else should I read?" Research Rabbit makes network search fast. Once you have the paper set, pair it with Atlas or Elicit for the next step. Research Rabbit is free.
- Pros: visual paper maps, fast seed-paper expansion, free access.
- Cons: no source-grounded answer generation.
- Use case: enter a new field from a seed paper set.
7. SciSpace: Best for paper reading and literature-review agents (H/V 0.16)
SciSpace calls itself an AI research assistant for academics. It offers review workflows, PDF chat, and a large paper index. It fits the reading layer between paper search and final synthesis.
SciSpace is strongest when you need to understand papers quickly. Its PDF chat and review agents help summarize, compare, and explain papers. It is weaker than Atlas for private-source synthesis. It is weaker than Elicit when you need strict data tables.
- Pros: paper reading, PDF Q&A, broad research index, review agents.
- Cons: less controlled for final synthesis than a corpus-first workspace.
- Use case: read and explain papers before moving the final source set into Atlas or Elicit.
We do not rank broad web-search assistants as academic research software here. Perplexity or ChatGPT can surface general context, but they are risky for cited science work where source accuracy matters.
Benchmark Comparison Table
The benchmark table above scores all 7 tools on the 5 proof points from the brief. Citation grounding shows how close the link gets to the claim. Hallucination rate shows source risk. Synthesis depth shows answer depth. Discovery coverage shows paper search reach. Price-per-query shows budget pressure.
Atlas wins when synthesis over an uploaded source set is the bottleneck. Elicit wins when the job is structured extraction. Semantic Scholar and Research Rabbit win before you have the corpus.
How to Choose Your AI Research Assistant
Most working researchers run 2 or 3 tools. The benchmark above shows which phase each tool wins. Pick the tool that fits the current phase of work, whether that is discovery, extraction, or synthesis. Check source accuracy, database coverage, and workflow fit.
If you already have a paper set, Atlas fits after discovery. If you still need to find papers, start with Semantic Scholar or Research Rabbit first.
For Academic Literature Reviews
- Discover, Semantic Scholar (TLDR + alerts) plus Research Rabbit (citation network).
- Screen and extract, Elicit. The extraction-table feature is the entire reason this stack exists.
- Verify before citing, Scite. Run every key citation through Smart Citations before it lands in your draft.
- Synthesize the argument, Atlas. The mind map across your loaded corpus surfaces the structure your paper will follow.
This stack is heavier than necessary for a single course paper. It fits a thesis chapter or a peer-reviewed submission well. Read our complete guide to AI for literature reviews for the detailed workflow.
For Graduate Research
- Ongoing search, Semantic Scholar alerts on your topics. Lightweight, free, automatic.
- Deep reading and annotation, Atlas. Upload, chat with, and connect papers as you read.
- Quick checks during writing, use Consensus when the question is empirical and SciSpace when you need to explain a paper.
- Before you submit, run Scite Smart Citations on every cited finding.
For Professional and Industry Research
- Fast cited answers, Consensus for peer-reviewed questions and SciSpace for paper reading.
- Deep dives across reports, Atlas. Upload the analyst reports, technical notes, and PDFs you already have, then query across them.
- Academic evidence layer, Elicit when a decision needs structured evidence to back it.
For Students
- Course papers, Semantic Scholar (free) for finding sources, Atlas ($20/mo Pro) for understanding and connecting them.
- Exam preparation, Atlas for synthesizing course materials across lecture notes, slide decks, and readings.
- Quick references during writing, Consensus or SciSpace.
- Single-PDF chat, see our chat-with-PDF AI tools roundup for lighter alternatives.
Next steps for source-grounded synthesis
If paper search is done, synthesize your research corpus with cited answers in Atlas. If search is still open, build the source list first. Then bring the final set into Atlas.
What AI research assistants still cannot do
Three failure modes recur across every tool in this guide. They matter because they define the boundary between tasks you can delegate and tasks you cannot.
No tool can reliably judge whether a study design fits the research question. Sample size, control groups, and field fit still need human expertise. Scite gets closest by showing citation context, but the judgment is still yours.
No AI tool searches every database. Systematic reviews submitted to peer review still need a manual database search along with the AI workflow. AI reduces the burden, but it does not replace the requirement. See our guide to AI systematic review tools.
A paper can be highly cited and still be weak. AI tools cannot make that quality call for you. Scite's "contrasting" label helps, but it still depends on human reviewers.
As discussed above, long context does not solve source drift by itself. Watch tools that pair retrieval with a structured graph, especially Atlas and Scite. For more, see AI tools that don't hallucinate and AI with references.
Privacy and training data
Ask these privacy questions before you upload sensitive work:
- Is uploaded content used to train models? Atlas, Elicit, Consensus, and Scite document "no". Check SciSpace plan terms before uploading sensitive work.
- Is the upload encrypted in transit and at rest? Industry standard yes across all tools tested.
- What is the deletion guarantee on cancellation? Varies. Atlas, Elicit, and Consensus document a deletion window, while the others require checking the specific terms.
- Does the provider store your queries? Yes for all of them, for product-improvement purposes. Opt-outs vary.
For sensitive work, keep the source set local if policy requires it. That includes drafts, clinical data, and private company work. None of the cloud tools here is built for that strict workflow.
Migration: how to move between research stacks
Researchers often ask, "How do I switch without losing my library?" 3 patterns work:
When leaving Zotero or Mendeley for an AI tool, export to BibTeX and PDF folders first. Atlas, Elicit, and Scite all import from Zotero directly, and the metadata round-trips cleanly. See our Zotero alternatives guide for the longer comparison.
When leaving a single AI tool for a stack, keep the discovery layer constant and swap the synthesis tool. Semantic Scholar can remain the front door. Your loaded papers and metadata travel, but the AI's annotations on them mostly do not.
When leaving an AI tool entirely, export the corpus to Markdown or BibTeX. AI-built links and clusters are derived state, so they will not survive the move. That is acceptable. The AI's value was in the discovery work itself. The derived links and clusters do not need to travel with the corpus.
Use the benchmark before buying
The most useful insight is the H/V table. Tools below 0.1 are strong for academic use with normal checks. Tools between 0.1 and 0.3 need active review. Do not use broad web-search answers as final cited evidence.
The lowest-friction entry stack for a researcher new to AI assistance is:
- Semantic Scholar, free, sign up, set up alerts on your topics today.
- Atlas, upload the papers you've been hoarding and let the mind map show what you have.
- Add one specialist. Choose Elicit for review tables. Choose Scite for source checks. Choose Consensus for quick evidence checks. Choose SciSpace for reading papers.
Research is hard enough without spending weeks on work an AI assistant can compress to hours. The practical choice is whether you trust a tool that keeps answers tied to sources.
If your source set is ready, synthesize your research corpus with cited answers. Check each answer against the linked passage before you write.
For more on research stacks, see AI tools for academic research, AI for literature reviews, and how to synthesize research papers. For nearby tool sets, see Elicit alternatives, literature review software, and academic research software platforms.
For tool-by-tool detail, compare Atlas with ChatGPT, Claude, Gemini, and Perplexity. Then compare research tools such as Covidence, Elicit, Scite, and Semantic Scholar. If your workflow starts from PDFs, the ChatPDF alternatives guide narrows the document-chat category.
Synthesize research papers with citations
Upload selected papers after discovery and inspect citations behind each answer.
Frequently Asked Questions
There is no single best tool because research has phases, and the tools split cleanly along them. Discovery is best handled by Semantic Scholar or Research Rabbit. Structured extraction across many papers is Elicit. Question-answering with peer-reviewed only is Consensus. Citation-context lookup is Scite. Cross-paper synthesis once your corpus is loaded is Atlas. Most working researchers run two or three of these in combination.